I’m sure you must have come across the term “data science” a large number of times till date. But have you ever given a deep thought to what is data science? what the duck does this term mean, and why is it even important?
Is it really some kind of science(as the name suggests), or some rocket science? Or something else other than all these stuffs?
Do you also get a thought that it is as scary as science or physics or chemistry used to be, back in the school days?
Or something entirely different?
Well, just a disclaimer 🙂
It’s certainly not as scary and complicated as you may be finding physics or chemistry, in your high school days.
And it has almost nothing to do with the science which you have studied, back then.
” Data science is more about your intuition, your mindset, and how critically can you think and analyze a particular situation.”
Feeling more confident about data science now?
I’m sure you must be 😉
Let’s get ahead and learn what is data science, and why it is the most sought-after career in today’s scenario!
We’ll be covering step by step, each and everything about this apparently complicated term, and I promise to make you thoroughly understand the fundamentals side by side, as we proceed.
By the end, you’ll be thorough with the fundamental ideas behind data science, and all the aspects of it. Along with, you’ll have a clear pathway in your head regarding how to get started with your data science journey, what all skills you need to master to excel as a data analyst and data scientist, what kind of projects you may need to do for a good data science profile, and also how to crack any data science and analytics interview.
Overall, it’s going to be a complete package ripping apart the term Data Science.
So, let’s get started right away!!
What is data science?
Data science is nothing but an ecosystem that uses various tools and algorithms, which the primary goal to discover the hidden patterns or the kind of patterns that are not noticeable right away. The objective behind that is to leverage the data to improve the current processes and also predict future trends with as great accuracy as possible.
But, what’s even more important is fundamental to know is that why data science originated in the first place, and how has it reserved an integral position in the operations of any business whatsoever!!

As the digital world is expanding exponentially day by day, more and more data points are being collected by companies and even small businesses to provide the best user experience to their customers, and also improve the productivities of their own businesses. Now, with such a large set of customers, the data that these businesses end up collecting is enormous in size, which is also referred to as big data. Hence the need for storage of such data also grew exponentially, and it had become a major challenge in front of industries, back around 2010.
Hence, the main focus was building a framework and feasible solutions to store such data. Hadoop and some other frameworks were developed to solve the storage problem, and now the focus started to shift on how to use this data to our advantage.
Here’s where the secret sauce of Data Science stepped into the picture. All the imaginary-looking ideas you see in Hollywood sci-fi movies can turn into a reality with data science. Data science is the fuel of Artificial Intelligence, and hence, it becomes crucial for us to understand it in depth.
Now let’s get a bit into the technicalities. As I had told above, one of the basic objectives of data science is to discover hidden patterns and insights from raw data.
A very genuine question shall be revolving around your head.. How is data science different from statistics then?
How is the job of data science professionals different from what statisticians and even analysts have been doing for years?

The answer pretty much lies in the image shown above. As a matter of fact, statisticians and analysts bring out the reasons and explanations to what has happened, by first cleaning and then processing data using various tools and technologies. But a data scientist not only analyzes and brings out the insights but also uses machine learning to predict the future occurrence of an event. Hence, the job of a data scientist is much more typical as compared to an analyst.
Broadly speaking, analytics has been divided into 4 major categories. They are written in an order of complexity, starting from simple and least complex, and the sophistication and complexity of the analysis keep rising as we move up the categories. As a matter of fact, the more complex and higher category the analysis is, the more value it brings!
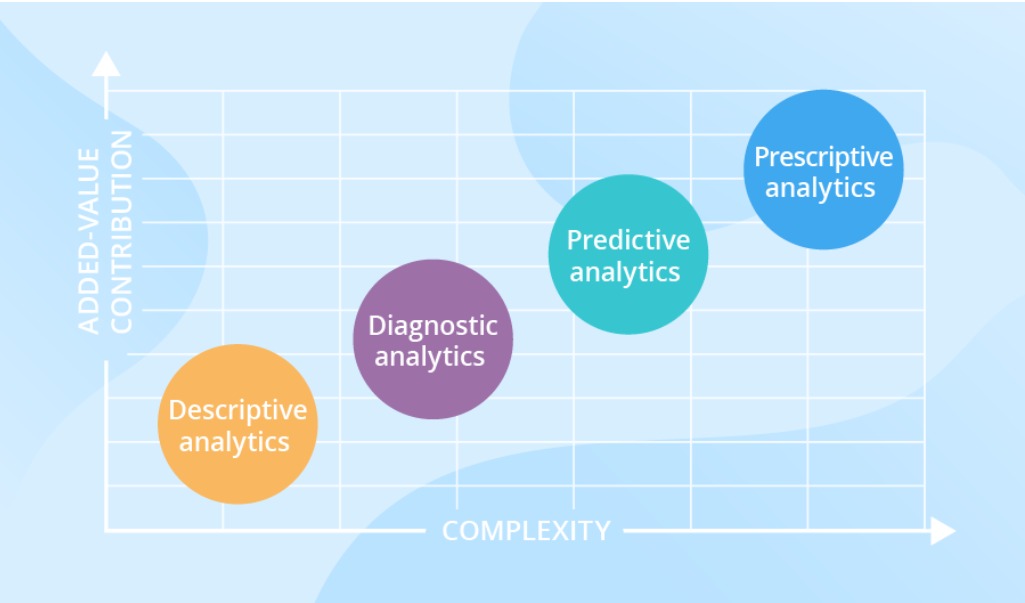
Descriptive analytics
Descriptive analytics answers the questions around what happened.
In this kind of analytics, raw data is juggled from multiple sources is juggled around to reveal valuable insights from the past. However, it just gives information about whether a decision was correct or not, without heading over to much explanation for it. For this reason, most businesses have started to combine different types of analytics rather than limiting to descriptive analytics.
Giving a short instance of what descriptive analytics is,
Let’s say a manufacturer analyses the monthly revenue obtained from each product group, and also the total quantity they manufactured per product group. Through this analysis, he’ll be able to answer the what happened questions, and he shall better be able to decide the focus product groups.
Diagnostic analysis
At this stage of analytics, the past data can be measured against other datasets to know why something happened. It gives opportunities to the businesses to rectify some mistakes right away and gives deeper insights into the problem. Ideally, companies should have detailed information at their disposal, else performing diagnostic analysis for every tiny problem shall lead to wastage of time and resources.
Just to give an example of what diagnostic analysis is, let’s consider a retailer who sells various categories of products. He can analyze and dig deep into the sales and gross profits down to the categories level, and find out why he missed his net profit target.
Predictive analytics
Predictive analytics essentially tells what is likely to happen. It puts into use the insights of descriptive and diagnostic analytics to detect the exceptions and outliers, and predict future trends, which makes this kind of analysis handy for forecasting. Predictive analytic is an advanced type of analytics and brings along sophisticated analysis and prediction technologies like machine learning or deep learning.
But t has to be kept in mind that:
Forecasting is just an estimate, based on past data. Its accuracy shall be highly dependent on the quality of data, and stability of the situation. Hence, it needs to be treated carefully and optimized at regular intervals.
Prescriptive analytics
A number of data science enthusiasts confuse themselves between predictive and prescriptive analytics, so understand it carefully. In a real sense, prescriptive analytics prescribes what action has to be taken to eliminate the future problem predicted by predictive analytics. It uses many advanced technologies and complex machine learning algorithms, deep learning, and certain business rules, which makes it good enough to implement and manage on a large scale.
Just to give an example, let’s say a company is able to predict and identify opportunities for repeat purchases of customers, based on customer analytics and sales histories. It then acts accordingly and witnesses an increase in the LTV and revenue in the coming months.
Generally, it requires many types of external information as well due to the nature of the algorithms it depends upon. Due to this very factor, it’s recommended to weigh the efforts that have to be laid down, against the expected added value, and then decide whether to go for prescriptive analytics or not.
Now, let’s take a quick look at how machine learning has brought in the way the given types of analytics are executed.
ML for making predictions:
Let’s say you have the past transactional data of a finance-based company, and you want to analyze the future trends, then the machine learning algorithms are much more efficient, than any type of regular forecasting.
This essentially falls under the category of supervised learning.
It is called supervised because we train the machines based on the datasets available.
The credit card fraud detection project is a superb example of this type. The credit card fraud detection model can be trained using past transaction behaviors, which also include the locations of the transactions.
ML for pattern discovery:
If there is a lack of parameters for making the predictions, then you’ll need to discover the hidden patterns in order to make accurate predictions.
Since we don’t have the predefined group labels, in this case, it is known as the unsupervised model.
To obtain more clarity, just think of yourself working in a telecom company. Now the situation is such that you need to establish a network in a region, by putting up towers.
Now, to figure out the tower locations, such that the users receive optimum signal strength, the clustering technique, which is nothing but a machine learning algorithm, can be deployed.

Through the image, it can easily be figured out that data analytics primarily includes descriptive analytics and predictive analytics, to a small extent. Whereas data science is about descriptive analytics to a very small extent, and majorly about predictive analytics and machine learning
More about “Why Data Science”?
Now that you have multiple insights about why data science came into being in the first place, let’s look at some more limitations in the market, which resulted in the birth of data science and relevant technologies.
Till the last decade, the data sizes were small in size and were generally structured, hence could be easily analyzed using the then-trending tools like PowerBI and Tableau.
Unlike that time, in today’s scenario, the data is available in raw and unstructured or semi-structured formats most of the times since it is generated from random sources like text files, sensors, multimedia, etc. And traditional tools like PowerBI, Tableau, or Excel can’t essentially handle such large volumes of unstructured data.
Hence, the need for more efficient analytics was felt for analyzing and processing such big data, and there took the birth of complex machine learning algorithms and deep learning.
Data Science has a large number of applications in our day-to-day life, and we’ve ourselves been using the applications of AI and data science, without even realizing it.
The below infographic is enough to show how enormous a role is data science and its applications playing in our life.

Let’s also describe some of them in detail:
Searching through the web:
Many of you may not be knowing that Google search also uses data science technologies to index and rank the content within a fraction of a second.
Creating recommendation systems:
Have you noticed how fascinating it is the way Youtube, Netflix, Prime Video recommends us the videos or shows that we can watch next, and that more or less aligns without interests and likings.
Such recommendation systems are the gift of data science itself, and its no rocket science to build them. Using a recommendation tool, and implementing certain libraries are generally good to go for a basic recommendation system.
Gaming:
All these streaming channels like ESPN, Sony, Nintendo, etc are making use of data science technologies themselves. Games have now been starting to use machine learning techniques to enhance your gaming experience, and hence the UX.
Comparing prices online:
Websites like Shopzilla, PriceRunner work on the principles of data science, and these websites use APIs to fetch datasets from different E-commerce platforms like Amazon, Flipkart, etc.
Now, if you feel that you want to make your career in this ever-expanding field of data analytics and data science, mind my words start to work today itself! It’s a pretty rewarding field, and shall escort to new heights of success, if you have that zeal in yourself 🙂 I recommend you to read about how you can start your career in data analytics as a beginner, and how you can scale it up, in this article.
A day in the life of a data scientist:
Data scientists have to crack complicated problems dealing with data, to bring out the best and the most meaningful insights, for that particular aspect of the business. They keep playing around with various visualization and analysis tools to figure out the appropriate solutions.
In fact, the term data scientist has been coined since the extract, process, and make predictions out of a lot of information(data) from scientific resources, be it in structured or unstructured formats.

Let’s move a bit ahead and discuss, another term that is commonly mistaken with data science. i.e.- Business Intelligence. I’m sure you too must have heard this term and would have even heard of being interchangeably used with Data Science.
Both of these terms mean the same to a certain extent but have a very fundamental difference lying underneath.
Business intelligence focuses on past data to extract insights and analyze business trends. Business intelligence enables us to collect data from external and internal sources, run queries to process that data, and present it in the form of dashboards. It can answer certain business-related questions to a certain extent, but not an in-depth analysis.
It generally just involves the use of statistics and visualizations, to a large extent.
On the other hand, Data science takes a more constructive and foreseeing approach, and it looks to analyze the past datasets to predict what’s most likely to happen in the future.
It helps to make more informed and meaningful decisions, which are essentially data-driven instead of being intuition-driven.
Apart from just relying on statistics and visualization, it puts machine learning, neuro-linguistic programming, and graph analysis as well into action.
The lifecycle of a data science problem/project:
Any data science problem has to be approached strategically following a certain set of steps in order. Any step skipped shall result in inaccurate insights and predictions.
This is one of the most important questions to be asked in an interview for a data science role, since the understanding of the process, and the mindset is primary thing that a recruiter looks for in a candidate for a data science role, rest everything can be trained for. Check out this detailed guide for data scientist/data analyst interview questions, which covers each and every aspect of an interview for a data-related role.
The first phase is called the discovery phase, where it’s important to understand the scope of the problem, the business requirements, and other specifications linked to it.
At this stage, you make an assessment of whether you have the resources and manpower to take over the project, and what other assets may be required to execute the project.
Also, clearly defining the problem statement is very important in this stage itself, so as to you prevent yourself from deviating to unnecessary stuff, that may block our time and resources, without yielding any considerable output or insights.
The second phase is all about Data preparation. You’ll require an analytics sandbox to perform analytics for the entire duration of the project.
But you’ll have to explore, clean, and refine data before dragging it into the modeling stage.
Furthermore, you’ll be performing the ELT operations on the data to get it into the sandbox. ELT operations are nothing but Extracting, loading, and transforming. These operations are performed on big data as well before they are stored as OLAP cubes in the data warehouses.
Look at the below statistical analysis flowchart to understand the second phase of the data science project cycle better.

The third phase of the project cycle is planning the model.
Here, the data scientist looks to establish relationships between different variables, and these relationships set the tone for the algorithms you shall be implementing in the subsequent phase.
Model planning tools:
Some handy and really easy to use model planning tools are described below:
R: It is essentially a statistical tool, and not a programming language as considered by many people. It holds a good set of modeling capabilities and is a good platform for building exclusive explanatory models.
SQL Analysis Service: Using data mining techniques, it can perform certain analytics inside the database. It is not as extensively used as R because of its limitations regarding performing analytics.
SAS/ACCESS: SAS is generally deployed to access data from Hadoop, which is a data-storing technology. It is used in creating reusable models and is useful at those companies where the problem statements are fundamentally similar to each other, with slight variations.

The fourth phase is finally building the model. In this phase, we develop datasets that are used for training and testing the models. The accuracy of the model depends upon the number of factors the data (to be predicted) depends upon, just like how a machine learning model works. The more the number of factors on which the data(to be predicted) depends, the less is the accuracy of the model.
At this phase, we also need to figure whether our existing tools shall be sufficient to run the model or a more extensive environment is required. We employ more sophisticated techniques like classification, regression, and clustering for building the model.
Some more common tools for building the model are shared in the infographic below:

To know more about the general skills one needs to be an efficient data scientist, click here and read this beautiful guide which crisply mentions the kind of skills a data scientist must possess.
Now, that you’ve got ample knowledge regarding how to approach a data science project, you should work on this, and try to develop a problem-solver mindset as much as possible. To build a strong portfolio in this field, you’ll undoubtedly require some really good projects to be done, and that projects which solve a social problem shall highlight your portfolio more than anything else. Check out these amazing data science projects that shall give you an upper hand in this field.
Challenges in Data Science Technology:
I hope you have got to learn enough in this blog, and I’ll not make it very long to allow you the time to absorb it, I’ll cover the remaining aspects of data science like jobs in data science in the next article. At the end of this article, let’s discuss some of the challenges that data science professionals are facing even today. Of course, they’re coming up with smarter technologies day by day, but there are some fundamental challenges that almost every data science professional faces, on a general level.
–>High levels of information and datasets are required for the analysis to be considerably accurate.
–>Unavailablity/limited availability of quality data.
–>Results from data science are not satisfactorily executed by the decision-makers of the company, due to which their efforts go in vain
–>Also, there is a paucity of efficient data science professionals, although the quantity is large, unfortunately, not the quality.
I hope you learned a lot from this extensive article, and I also hope it must have widened your vision with resp data science and must have sowed the seed in your mind to keep learning more and more about the endless universe of data science.